Variational AutoEncoder 정리 - (1) Intro
Day 92
Variational AutoEncoder
- 참고자료
필요 배경지식
Maximum Likelihood Estimation

-
모델 출력값이 Given 될 때 우리가 원하는 정답(Ground Truth)이 나올 확률이 높길 바란다.
-
모델 출력값이 Given 될 때 원하는 정답이 나올 확률 즉 조건부 확률이다.
→ 조건부 확률의 분포 자체를 가정한다.
→ ex) 조건부 확률이 Gaussian 분포를 따를 것이다 가정.
-
가정한 확률분포에서 출력Y가 나올 가능도
→ Likelihood
→ 추정할 모델의 모수(모평균, 모분산)에 따라 그 값이 변함.
-
Maximum Likelihood Estimation
→ Likelihood를 최대로 하는 모수를 찾자.
→ Likelihood의 미분 값이 0이 되는 지점이 최대값을 가질 것이다.
→ log Likelihood의 미분 값이 0이 되는 지점을 찾아도 같은 지점일 것이다.
→ 추정한 모수가 Y의 평균, 분산과 같을때 최대일 것이다.


→ 확률 분포간의 거리를 나타내는 KL발산이 가장 낮을때 Likelihood가 최대일 것이다.
→ MLE로 찾은 모수에서 모델 출력값이 Given 될 때 원하는 정답이 나올 확률이 최대가 될 것이다.
MLE의 결론
- 입력 X가 주어졌을때 모델$f_{\theta }\left( \cdot \right)$을 거쳐 $\omega$를 출력한다. 이때 $\omega$는 MLE에 의해 가정한 Y의 분포를 가장 잘 나타내는 분포를 따르는 모델$f_{\theta }\left( \cdot \right)$의 출력값이다.
- $f_{\theta }\left( \cdot \right)$를 확률 분포로 모델링 했으므로 해당 확률 분포를 바탕으로 데이터 샘플링이 가능하다.
- 가장 큰 장점
- VAE에서 MLE를 활용하는 핵심 이유
MLE와 MSE, CE의 관계

(출처: http://videolectures.net/kdd2014-bengio_deep_learing/)
-
모델이 Gaussian 분포를 따른다고 가정하고 MLE을 한다는건 그 식을 정리하면 MSE를 구한다는 것과 의미가 같다.
→ Backpropagtion의 Loss로서 MSE를 사용하는 것과 큰 틀에서 의미가 같다.
-
모델이 Bernoulli 분포를 따른다고 가정하고 MLE을 한다는건 그 식을 정리하면 Cross Entropy를 구한다는 것과 의미가 같다.
→ Backpropagtion의 Loss로서 Cross Entropy 사용하는 것과 큰 틀에서 의미가 같다.
Manifold learning
Manifold(고차원 데이터를 공간에 흩뿌렸을 때 모든 데이터를 에러 없이 아우르는 곡면)을 나타내는 함수가 있을 것이다 해당 함수를 잘 찾아서 Projection을 시키면 데이터 압축이 가능할 것이다.

(출처: https://www.semanticscholar.org/paper/Algorithms-for-manifold-learning-Cayton/100dcf6aa83ac559c83518c8a41676b1a3a55fc0)
-
What is useful for?
- Data compression
- Data visualization
- Curse of dimensionality
- Discovering most important features
-
Reasnable distance metric



(출처: https://www.slideshare.net/NaverEngineering/ss-96581209 이활석님 강의자료)
단순 Euclidean distance보다 Manifold 곡면을 따라 거리를 측정하는게 더 Reasonable하다.
AutoEncoder


(출처: https://www.slideshare.net/NaverEngineering/ss-96581209 이활석님 강의자료)
x 를 Encoder h(.)를 거친 latent z로 압축하고, z를 Decoder g(.)를 거쳐 y로 복원했을때 Recostruction Error 줄어드는 방향으로 학습시킴.
Keyword
- Unsupervised learning
- ML density estimation
- Generative model learning
- Manifold learning
AutoEncoder의 가장 중요한 기능 중 하나는 Manifold learning이다.
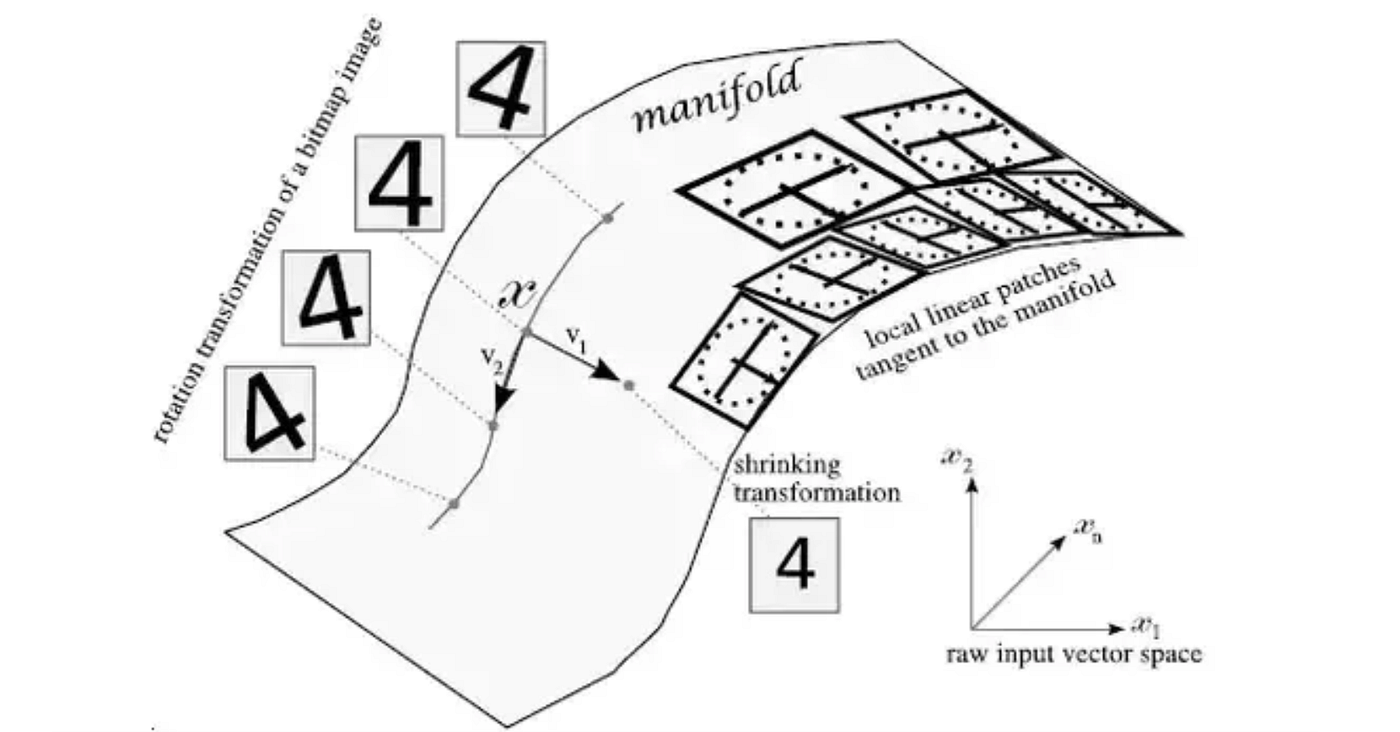
출처: https://towardsdatascience.com/manifold-learning-t-sne-lle-isomap-made-easy-42cfd61f5183
의도하고 학습을 시킨게 아니었지만 찾은 Manifold 공간이 의미있는 Representaion을 자동으로 가졌다. 곡면을 따라 v1 방향으로 이미지를 샘플링 하면 숫자가 작아지는 효과가 있었고, 곡면을 따라 v2 방향으로 이미지를 샘플링하면 회전하는 효과가 있었다.
Leave a comment