부스트캠프 AI 4주차(Day-22 ~ Day-26) 회고록
Day 22
- 쉬는 날이었지만 Dive Into Deep Learning 17장을 팀원들과 리뷰했다.
- 17.7 Sequence-Aware Recommender Systems
- 17.8 Feature-Rich Recommender Systems
- 17.9 Factorization Machines
- 17.10 Deep Factorization Machines
- 7.1 From Fully Connected Layers to Convolutions
Day 23
- 이고잉님의 깃허브 특강-1
- git init
- git checkout
- HEAD와 MASTER(Main)
- detached head
- git branch
- git merge
- 추천 시스템 문제정의
- 유저가 접할 수 있는 정보의 양이 다양해지며 정보를 찾는데 시간이 오래 걸림.
-
Few Popular items → Long Tail Phenomenon

- 사용 데이터
- 유저 관련 정보
- 아이템 관련 정보
- 유저 - 아이템 상호작용 정보
- Explicit Feedback
- 유저에게 아이템에 대한 만족도를 직접 물어본 경우.
- Implicit Feedback
- 유저가 아이템을 클릭하거나 구매한 경우.
- Explicit Feedback
- 특정 유저에게 적합한 아이템을 추천한다. or 특정 아이템에게 적합한 유저를 추천한다.
- 유저 - 아이템 상호 작용을 평가할 score 값이 필요하다.
- 추천을 위한 score는 어떻게 구해지고 사용하는가?
- 랭킹 또는 에측
- 랭킹: 유저에게 적합한 아이템 Top K개를 추천하는 문제
- 평가 지표: Precision@K, Recall@K, MAP@K, nDCG@K
- 예측: 유저가 아이템을 가질 선호도를 정확하게 예측. (평점 or 클릭/구매 확률)
- 평가 지표: MAE, RMSE, AUC
- 랭킹: 유저에게 적합한 아이템 Top K개를 추천하는 문제
- Offline Test
- AP@K \(\dfrac{1}{m}\sum ^{k}_{i=1} Precisiom@i\)
- MAP@K \(\dfrac{1}{ |{U}| }\sum ^{|{U}|}_{u=1} (AP@K)_{u}\)
-
NDCG

- Onlie Test
- 실제 추천 결과를 서빙하는 단계.
- 동시에 대조군(A)과 실험군(B)의 성능을 평가.
- Traffic을 50% 50%로 나눠 서빙 해봄.
- 모델 성는이 아닌 매출, CTR 등의 비즈니스 서비스 지표로 평가.
- 인기도 기반 추천
- Most Popular
- Highly Rated
- Hacker News Formula
- Reddit Formula
- Steam Rating Formula
- 추천 시스템에서 딥러닝의 한계
- 추천 시스템은 Deep Learning으로 얻을 수 있는 성능의 향상폭이 CV나 NLP에 비해 크지 않다.
- 많은 유저들의 트래픽이 몰리는 곳에서 서비스 하는 경우가 많기 떄문에 모델의 Inference Time 즉 Latency가 중요함.
- 연관 규칙 분석(Association Rule Analysis)
- 상품의 구매, 조회 등 하나의 연속된 거래들 사이의 규칙을 발견하기 위해 적용함.
- 흔히 장바구니 분석 혹은 서열 분석이라고도 불림.
- ex) 맥주와 기저귀를 같이 구매하는 빈도가 얼마나 되는가?
- itemset
- frequent itemset
- support count
- support
- confidence
-
lift




- lift 값을 내림차순 정렬하여 의미 있는 rule을 평가함.
- 주의할 점은 이 rule 어떠한 상관관계를 의미하는 것은 아님.
- 실제로 연관 규칙 분석을 활용할 때는 모든 연관 규칙을 구하는 Brute-force가 아닌 Apriori, DHP, FP-Growth 등의 알고리즘을 활용한다.
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 유저가 선호하는 아이템을 기반으로 해당 아이템과 유사한 아이템을 추천.
- 컨텐츠 기반 추천
- 장점
- 유저에게 추천을 할 때 다른 유저의 데이터가 필요하지 않음 .
- 새로운 아이템 혹은 인기도가 낮은 아이템을 추천할 수 있음 .
- 추천 아이템에 대한 설명이 가능함.
- 단점
- 아이템의 적합한 피쳐를 찾는 것이 어려움.
- 한 분야/장르의 추천 결과만 계속 나올 수 있음.
- 다른 유저의 데이터를 활용할 수 없음.
\[TF-IDF\left(w ,d\right) = TF\left(w ,d\right) \cdot IDF(w)\]
- 장점
피어세션: 멘토님이 만들어 주신 질문에 각자 팀 노션에 답을 달아보는 시간을 가졌다.
Day 24
- Collaborative Filtering
- Neighborhood-based CF (NBCF)
- 구현이 간단하고 이해가 쉽다.
- 아이템이나 유저가 계속 늘어날 경우 확장성이 떨어진다. (Scalability)
- 주어진 평점/선호도 데이터가 적을 경우, 성능이 저하된다. (Sparsity)
- NBCF를 적용하려면 적어도 sparsity ratio*가 99.5%를 넘지 않는 것이 좋음.
- K-Nearest Neighbors CF (KNN CF)
- 유저 가운데 유저 u와 가장 유사한 K명의 유저(KNN)를 이용해 평점을 예측.
- 유사하다는 것은 우리가 정의한 유사도 값이 크다는 것을 의미함.
- 유저 가운데 유저 u와 가장 유사한 K명의 유저(KNN)를 이용해 평점을 예측.
- Similarity Function
- Mean Squared Difference Similarity
- Cosine Similarity
- Pearson Similarity
- Jaccard Similarity
- Rating Prediction
- Weighted Average
- 유저 간의 유사도 값을 가중치(weight)로 사용하여 rating의 평균을 냄.
- Absolute Rating Formula vs Relative Rating Formula
- 유저가 평점을 주는 기준이 제각기 다르다. 이 점을 보완하기 위해 편차를 활용한다.
- Weighted Average
- Model Based CF(MBCF)
- MBCF의 특징
- 데이터에 숨겨진 유저-아이템 관계의 잠재적 특성/패턴을 찾음.
- 모델 학습/서빙으로 이미 학습된 모델을 통해 추천하기 때문에 서빙 속도가 빠름.
- Sparsity / Scalability 문제 개선.
- Overfitting 방지.
- NBCF는 주변 특정 데이터로 학습하지만 MBCF는 데이터 전체에 대해 학습하기 때문.
- Limited Coverage 극복
- NBCF의 유사도 값이 정확하지 않은 경우 이웃의 효과를 보기 어려우나 MBCF는 이 한계를 극복했다.
- Latent Factor Model(Embedding)
- 유저와 아이템 관계를 잠재적 요인으로 표현할 수 있다고 보는 모델.
- 유저-아이템 행렬을 저차원의 행렬로 분해하는 방식으로 작동.
- 같은 벡터 공간에서 유저와 아이템 벡터가 놓일 경우 유저와 아이템의 유사한 정도를 확인할 수 있음.
- MBCF의 특징
- Neighborhood-based CF (NBCF)
-
Matrix Factorization (MF)

- Alternative Least Square (ALS)
- Implicit Feedback 데이터에 적합하도록 MF 기반 모델을 설계하여 성능을 향상시킨.
- 유저와 아이템 매트릭스를 번갈아가면서 업데이트 두 매트릭스 중 하나를 상수로 놓고 나머지 매트릭스를 업데이트 pu, qi가운데 하나를 고정하고 다른 하나로 least-square 문제를 푸는 방법.
-
Sparse한 데이터에 대해 SGD 보다 더 Robust 하며 대용량 데이터를 병렬 처리하여 빠른 학습 가능.

- Bayesian Personalized Ranking
- 17.5. Personalized Ranking for Recommender Systems
- Bayesian을 활용해 사용자에게 순서(Ranking)가 있는 아이템 리스트를 제공하는 문제.
- 가정을 통해 Implicit의 정보를 좀 더 적극적으로 활용한다.
-
Bayes 정리를 활용해 Maximum A Posterior 구한다.

- Word2Vec
- Neural Network 기반 모델
-
임베딩(Embedding): 주어진 데이터를 낮은 차원의 벡터(vector)로 만들어서 표현하는 방법.
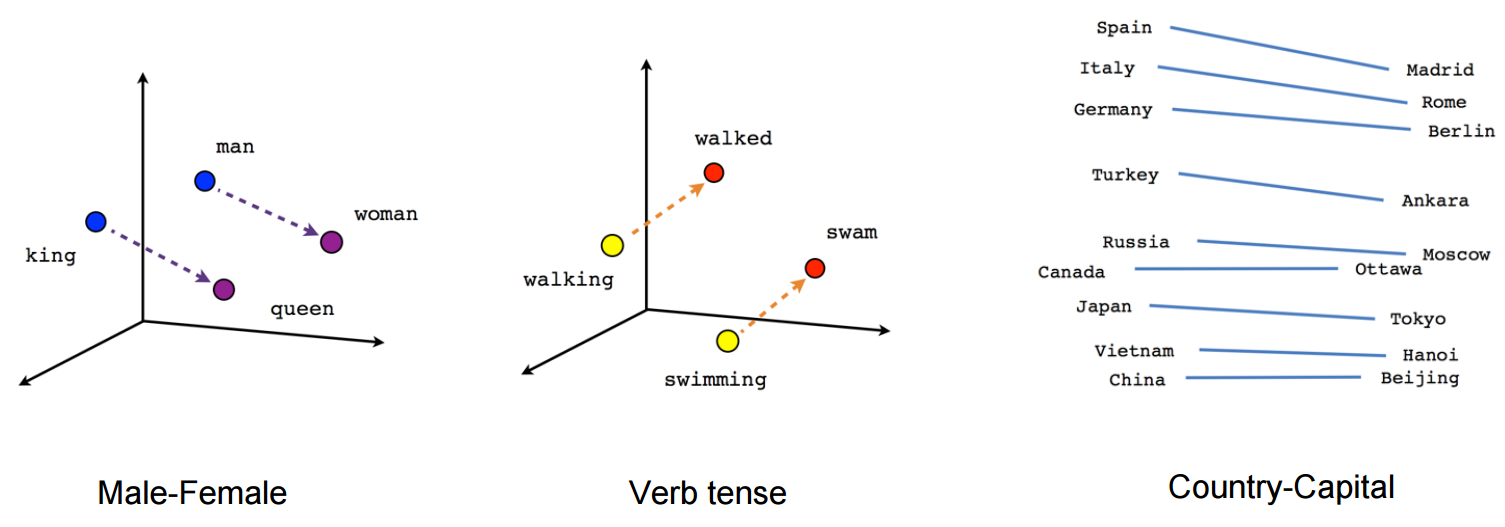
출처: https://towardsdatascience.com/mapping-word-embeddings-with-word2vec-99a799dc9695
- 대량의 문서 데이터셋을 vector 공간에 투영.
- 물리적으로 어떤 문장 안에서 가까이 있는 단어는 서로 연관성이 있을 것이다.
- 압축된 형태의 많은 의미를 갖는 dense vector로 표현.
- Continuous Bag of Words(CBOW)
- 주변에 있는 단어를 가지고 센터에 있는 단어를 예측하는 방법.
- 중앙 단어를 기준으로 앞뒤 n개의 단어를 입력해 중앙 단어를 예측하는 방법.
- 2n개의 임베딩 벡터를 평균내는 과정이 필요함.
- Skip-Gram
- CBOW의 입력층과 출력층이 반대로 구성된 모델.
- 벡터의 평균을 구하는 과정이 없음.
- 중앙 단어를 입력으로 넣어 임베딩한 벡터로 주변단어를 Mulit Classification.
- 일반적으로 CBOW보다 Skip-Gram이 성능(예측 정도가 아닌 임베딩 벡터의 표현력)이 좋다고 알려져 있음.
- Skip-Gram w/ Negative Sampling (SGNS)
- Negative Sampling
- Positive sample 하나당 K개의 Negative을 샘플링함.
- 학습 데이터가 적은 경우 5-20, 충분히 큰 경우 2-5가 적당함.
- 중앙 단어, 입력 단어를 입력받아 주변에 있는지 여부를 정하는 Binary Classification으로 바뀜.

- Negative Sampling
- Item2Vec
- 유저가 소비한 아이템 리스트를 문장으로, 아이템을 단어로 가정하여 Word2Vec 사용.
- SGNS 기반의 Word2Vec을 사용하여 아이템을 벡터화하는 것이 최종 목표.
- 유저 혹은 세션 별로 소비한 아이템 집합을 생성함 이 때 시퀀스를 집합으로 바꾸면서 공간적/시간적 정보는 사라짐.
- 집합 안에 존재하는 아이템은 서로 유사하다고 가정함.
- 아이템 집합 내 아이템 쌍들은 모두 SGNS의 Positive Sample이 됨.
- SVD(MF) 보다 임베딩이 더 잘됨.

- ANN
- 기존의 Brute Force KNN은 모든 Vector와 유사도 비교를 수행해야 함.(너무 느림)
- 정확도를 조금 포기하고 아주 빠른 속도로 주어진 Vector의 근접 이웃을 찾아볼까? → ANN
- ANNOY: spotify에서 개발한 tree-based ANN 기법.
- 벡터의 차원이 100개 이하일 때 적합.
- GPU 연산은 지원하지 않음.
- Search 해야 할 이웃의 개수를 알고리즘이 보장함.
- 파라미터를 조정 통해 accuracy / speed trade-off 조정 가능.
- 기존 생성된 binary tree에 새로운 데이터를 추가할 수 없음.
- Hierarchical Navigable Small World Graphs (HNSW)
- 벡터를 그래프의 node로 표현하고 인접한 벡터를 edge로 연결 후 Layer를 여러 개 만들어 계층적으로 탐색을 진행.
- Layer 0에 모든 노드가 존재, 최상위 Layer로 갈수록 개수가 적음. (랜덤 샘플링)
- Inverted File Index (IVF)
- 주어진 vector를 clustering을 통해 n개의 cluster로 나눠서 저장.
- vector의 index를 cluster별 inverted list로 저장.
- Product Quantization - Compression
- 기존 vector를 n개의 sub-vector로 나눔.
- 각 sub-vector 군에 대해 k-means clustering을 통해 centroid를 구함 .
- 기존의 모든 vector를 n개의 centroid로 압축해서 표현.
- PQ와 IVF를 동시에 사용해서 더 빠르고 효율적인 ANN 수행 가능.
의문점: ANN 에서 priority queue를 어떻게 사용하는가?


답: Section을 나눌 때 그림처럼 인접한 부분은 비슷한 Section으로(비슷한 색으로) 나누고 우선순위 정하며 Tree을 구성한뒤 가정 인접한 곳이 해당 노드에 없을때 queue 규칙에 맞게 트리를 타고 올라가 다음 탐색을 시행한다.
의문점: SGNS에서 임베딩 2개를 다음 layer로 사용한다는 부분이 이해가 잘 안됐다.
피어세션:Cross Entrophy를 줄이는 방향으로 학습한다고 한다. Cross Entrophy 부분이 기억이 잘안나서 복습해야겠다.
Day 25
- Recommender System with Deep Learning
- Nonlinear Transformation
- 선형 조합의 모델은 user와 item 사이의 복잡한 관계를 표현하는 것에 한계를 가짐.
- Representation Learning
- Raw data로부터 feature representation을 학습해 사람이 직접 feature design하지 않아도 됨.
- Sequence Modeling
- DNN은 자연어처리, 음성 신호 처리 등 sequential modeling task에서 성공적으로 적용됨.
- 추천 시스템에서 next-item prediction, session-based recommendation에 사용됨.
- Flexibility
- Tensorflow, PyTorch 등 다양한 DL 프레임워크 오픈.
- Nonlinear Transformation
- Neural Collaborative Filtering
- MF의 한계를 지적하여 신경망 기반의 구조를 사용해 더욱 일반화된 모델을 제시한 논문.
- MLP와 GMF를 결합.
-
GMF와 MLP는 서로 다른 embedding layer를 사용.

- YouTube Recommendation
- Scale
- 엄청 많은 유저와 아이템 vs 제한된 컴퓨팅 파워.
- 효율적인 서빙과 이에 특화된 추천 알고리즘 필요.
- Freshness
- 잘 학습된 컨텐츠와 새로 업로드 된 컨텐츠를 실시간으로 적절히 조합해야 함.
- Noise
- 높은 Sparsity, 다양한 외부 요인으로 유저의 행동을 예측하기 어려움.
- Implicit Feedback, 낮은 품질의 메타데이터를 잘 활용해야 함.
- Candidate Generation과 Ranking 두 단계로 이루어짐.
- Candidate Generation
- High Recall 목표, 주어진 사용자에 대해 Top N 추천 아이템 생성.
- 특정 시간(t)에 유저 U가 C라는 context를 가지고 있을 때, 비디오(i) 각각을 볼 확률을 계산.
- 비디오가 수백만 개나 되기 때문에 Extreme 결국 마지막에 Softmax 함수를 사용하는 분류 문제.
- 과거 시청 이력과 검색 이력을 각각 임베딩 마지막 검색어가 너무 큰 힘을 갖지 않도록 평균 냄.
- 성별 등의 인구통계학 정보와 지리적 정보를 피쳐로 포함.
- 모델이 과거 데이터 위주로 편향되어 학습되는 문제시청 로그가 학습 시점으로부터 경과한 정도를 피쳐로 포함.
- 다양한 feature 벡터를 한 번에 concat한 후 n개의 dense layer를 거쳐 User Vector를 생성함.
- 최종 Output layer는 비디오를 분류하는 softmax.
- 유저를 input으로 하여 상위 N개 비디오를 추출, 유저 벡터와 모든 비디오 벡터의 내적을 계산.(Annoy, Faiss 등을 활용)
- Ranking
- 유저, 비디오 피쳐를 좀 더 풍부하게 사용 스코어를 구하고 최종 추천 리스트를 제공.
- CG 단계에서 생성한 비디오 후보들을 input으로 하여 최종 추천될 비디오들의 순위를 매기는 문제.
- Logistic 회귀를 사용하는 기본적인 방법.
- loss function에 단순한 클릭 여부가 아닌 시청 시간을 가중치로 한 값을 반영.
- 단순 binary가 아닌 weighted cross-entropy loss 사용.
- 비디오 시청 시간으로 가중치를 줌.
- 낚시성/광고성 콘텐츠를 업로드하는 어뷰징(abusing) 감소.
- user actions feature: 유저가 특정 채널에서 얼마나 많은 영상을 봤는지, 유저가 특정 토픽의 동영상을 본지 얼마나 지났는지, 영상의 과거 시청 여부 등을 입력.
- DL 구조보다는 도메인 전문가의 역량이 좌우하는 파트.
- Candidate Generation
- 딥러닝 기반 2단계 추천을 처음으로 제안한 논문.
- 이 모델을 가지고 어떻게 서빙을 해야 현업에서 사용할 수 있는지까지 제시한 논문.
- Scale

Total Model

Candidate Generation

Ranking
- AutoREC
- Autoencoder: 입력 데이터를 출력으로 복원(reconstruct)하는 비지도(unsupervised) 학습 모델.
- Denoising Autoencoder: 입력 데이터에 random noise나 dropout을 추가하여 학습 noisy input을 더 잘 복원할 수 있는 robust한 모델이 학습되어 전체적인 성능 향상.
- Rating Vector를 입력과 출력으로 하여 Encoder & Decoder Reconstruction 과정을 수행.
- 유저 또는 아이템 벡터를 저차원의 latent feature로 나타내 이를 사용해 평점 예측.
- 아이템과 유저 중, 한 번에 하나에 대한 임베딩만을 진행.
- 관측된 데이터에 대해서만 역전파 및 파라미터 업데이트 진행.
- 기존의 rating과 reconstructed rating의 RMSE를 최소화하는 방향으로 학습.
-
Hidden unit의 개수가 많아질 수록 RMSE가 감소함을 보임.

- CDAE
- Denoising Autoencoder를 CF에 적용하여 Ranking을 통해 top-N 추천에 활용한 논문
- 문제 단순화를 위해, 유저-아이템 상호 작용 정보를 이진(0 또는 1) 정보로 바꿔서 학습 데이터로 사용
- AutoRec과 다르게 DAE를 사용하여 noise 추가
- 개별 유저에 대해서 +$를 학습 (Collaborative)
- 최종성능을 NDCG로 평가
- Matrix Factorization 모델 직접 구현(과제)
의문점: CDAE에서 개별 유저에 대해서 파라미터 Vu 를 학습하고 이 때문에 Collaborative한 모델이라고한다. Collaborative의 정의에 대해서 다시 살펴봐야겠다. 강의 중 이렇게 말하셨다.
"각각의 유저별로 특징이 다르고 그 특징이 각각의 파라미터로 학습되며 이 모델이 Collaborative가 되었다."
피어세션: NCF 모델 구현 과제중 MF와 MLP의 feaure가 다른 부분에 대해 같이 고민했다.
Day 26
- Alternative Least Squares 직접 구현(과제)
- Neural Collaborative Filtering 모델 직접 구현해보기
- AutoRec 모델 직접 구현해보기
- Item2Vec 모델 직접 구현해보기
회고
이번 주는 본격적으로 RecSys 도메인에 대해 학습할 수 있었다. 특히 Youtube 관련 모델은 유튜브 알고리즘에 신기하고 성능에 놀랐던 적이 많아서 재밌고 흥미로웠다. 그러나 그 만큼 학습량이 많고 어려웠다. RecSys에 밀려 Data visualization 부분을 제대로 학습하지 못한 거 같다. 주말간 보충해야겠다.
Leave a comment