CS50 2019 강의후기 및 정리
모두를 위한 컴퓨터 과학(CS50 2019) 강의후기 및 정리
배경
부스트 캠프에 지원하고자 지원에 앞서 부스트 캠프에서 제공하는 CS50 이라는 강의를 들었다. 대학교 전공 수업으로 C언어를 배운적이 있었다. 그때는 재밌으면서도 어려웠던 기억이 있는데, 이 강의는 실생활과 연관된 도구를 잘 활용해서 알기쉽게 잘 설명 해주는것 같다. 정말 입문자에게 꼭 필요한 강의이다.

C 언어 주요내용 정리
타입
-
C 언어는 머신과 가까운 로우레벨의 언어라 데이터가 메모리에 어떻게 저장될지 그리고 프로그램에서 어떻게 처리해야 하는지를 명시적으로 알려주어야한다. 그래서 파이썬이나 자바스크립트와 다르게 변수의 타입을 항상 지정해 주어야한다.
이름 역할 바이트(byte) char 문자 1 int 4 4 float 단일 부동소수점 4 double 두배 부동소수점 8
make와 clang
- 전처리(Preprocessing)
- #include
와 같이 코드에 포함된 헤더 파일의 필요한 코드를 직접 가져온다.
- #include
- 컴파일(Compile)
- c 코드를 머신언어로 변환하기전 c코드와 머신언어의 중간단계인 어셈블리어로 먼저 컴파일 한다.
- 어셈블(Assemble)
- 어셈블리어를 조합해 0과 1로 이루어진 머신언어로 변환한다.
- 링크(Link)
- 컴파일된 파일과 실행에 필요한 여러개의 오브젝트 파일을 하나의 실행파일로 묶어준다.
clang은 컴파일시 별도의 링크 작업이 필요하지만, make는 링크 컴파일 빌드를 모두 처리해준다.
구조체
- 구조체란 C언어에서 새로운 타입을 임의로 선언하는 것을 말한다. 키워드는 typedef struct이다.
typedef struct { string name; string number; } people; people person; person.name = "EMMA" person.number = "617-666-0100"
포인터
- 데이터가 실제로 저장되어있는 메모리의 주소를 저장하는 변수를 포인터라고 한다.
- 변수를 &과 함께 사용하면 변수의 실제값을 저장하고 있는 주소값으 반환한다.
- 포인터에 쓰이는 *는 문맥에 따라 그 의미가 변하는데 말 그대로 가리킨다(Go there)라는 의미로 받아들이는게 편한다.
- 포인터형으로 선언된 변수 앞에 *가 붙는다 해당 주소가 가르키는 곳으로 가 그 값을 가져오라는 역참조이다.
- 포인터형 변수를 선언할때 *는 해당 변수가 포인터라고 선언하는 것이다.
#include <stdio.h> int main(void) { int n = 50; int *p = &n; // 포인터 변수형으로로 p를 선언, n의 주소를 반환하는 &연산자로 n의 주소 저장 printf("%p\n", p); //포인터의 포맷형 %p printf("%i\n", *p); // p가 실제로 가리키고 있는 실제 값을 불러옴 }
포인터와 문자열
- 문자열의 특징: 문자의 배열이고, 문자는 하나당 1byte를 차지한다 그리고 문자열의 종료는 8개의 0으로 이루어진 \n 을 통해 판단할 수 있다.
- 이를 포인터와 연관지어보면, 문자열의 가장 앞을 가리키고 있는 포인터를 알고 있다면 해당 문자열을 \n을 만나기전까지 1byte씩 이동하며 살펴보면 문자열에 모두 접근할 수 있다.
- 실제로는 string이라는 자료형은 존재하지않고 문자들의 배열의 첫 시작을 포인터로 가리키고 있을 뿐이다. 다시말해
string은typdef char *s로 완벽하게 대체할 수 있다. 더 엄밀히 말하자면string은typdef char *s를 보기좋게 구조체로 정리 했을뿐이다.#include <stdio.h> int main(void) { char *s = "EMMA"; printf("%p\n", s); // E를 저장하고 있는 메모리의 주소를 출력 (문자열 첫번째 문자의 주소) } // 배열과 포인토 둘 모두 같은 동작을 할 수있다. // 배열 인덱스로 접근 printf("%p\n", &s[0]); // E printf("%p\n", &s[1]); // M printf("%p\n", &s[2]); // M printf("%p\n", &s[3]); // A // 포인터로 접근 printf("%c\n", *s); // E printf("%c\n", *(s+1)); // M printf("%c\n", *(s+2)); // M printf("%c\n", *(s+3)); // A
문자열 복사
- 문자열은 결국 포인터로 접근하는것을 알 수 있었다. 때문에 call by value가 아닌 call by reference이다. 때문에 문자열을 다룰때 문자열에 변화를 가한다면 해당 메모리를 참조하고 있던 모든 변수에 변화를 가져온다. 이런 사이드 이펙트를 막기위해선 새로운 메모리에 문자열을 할당한 뒤 조작해야한다.
- 메모리를 변수에 직접 할당하는 함수는 malloc(SIZE)이며, SIZE 만큼의 바이트를 할당한다. 타입에 따른 size는 직접 입력하기 보다는 sizeof(TYPE)으로 표기한다.
- 여기서 문자열은 문자열의 길이에 사이즈가 달라지므로 string.h 헤더의 strlen(STR)함수를 활용한다. 주의할 점은 맨 마지막의 \n 까지 복사를 해야하므로 strlen(STR) + 1 의 사이즈로 메모리를 할당해야한다.
- toupper는 문자열을 대문자로 바꾸어 주는 함수이며, 소문자의 아스키라면 대문자의 아스키만큼 더해주는 역할이다. 또한 ctype.h 헤더에 저장되어있다.
-
malloc 함수를 쓰고나서는 메모리의 최적화를 위해 항상 프로그램 종료전에 free로 메모리를 비워줘야한다.
#include <cs50.h> #include <ctype.h> #include <stdio.h> int main(void) { string s = get_string("s: "); string t = s; t[0] = toupper(t[0]); // t의 첫글자를 대문자로 변환 printf("s: %s\n", s); // E 의도치 않은 버그(call by reference) printf("t: %s\n", t); // E }#include <cs50.h> #include <ctype.h> #include <stdio.h> #include <string.h> int main(void) { char *s = get_string("s: "); char *t = malloc(strlen(s) + 1); // 새로운 메모리에 문자를 할당해 해결 for (int i = 0, n = strlen(s); i < n + 1; i++) { t[i] = s[i]; } t[0] = toupper(t[0]); printf("s: %s\n", s); printf("t: %s\n", t);
malloc 와 free
- 앞서 말했듯 maclloc(SIZE)함수로 메모리에 직접 사이즈를 할당해서 사용할 수 있고, 반드시 프로그램이 종료되기전에 해당 변수를 free로 메모리 할당을 풀어주어야 최적화된 메모리를 가용할 수 있다.
메모리 교환, 스택, 힙
- 메모리의 영역은 크게 4가지로 나뉩니다.
- 코드영역(Machine code): 실행할 프로그램의 코드 영역입니다.
- 데이터 영역(Globas): 전역변수, 정적변수의 영역 시작과 함께 할당되며, 프로그램이 종료되면 소멸합니다.
- 힙 영역(Heap): 사용자의 동적할당 영역입니다.
- 스택 영역(Stack): 함수의 호출과 관계되는 지역 변수와 매개변수가 저장되는 영역. 스택 영역은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸합니다.

- 변수의 값을 스왑 하는법
#include <stdio.h> void swap(int a, int b); int main(void) { int x = 1; int y = 2; printf("x is %i, y is %i\n", x, y); // x = 1, y = 2 swap(x, y); printf("x is %i, y is %i\n", x, y); // x = 1, y = 2 버그발생 } void swap(int a, int b) { int tmp = a; a = b; b = tmp; }함수 종료와 함께 할당되었던 메모리가 소멸되는 특징 때문에 위와 같이 변수를 스왑한다면 예상치 못한 버그가 생기게 된다. 스왑의 대상이 x, y가 아닌 함수 호출시 새로 스택영역에서 할당된 a ,b의 교환이 일어나기 떄문이다. 따라서 이를 회피하기 위해서 a, b의 변수에 x, y의 메모리를 포인터로 직접 할당해준다면 해결된다.
#include <stdio.h> void swap(int *a, int *b); int main(void) { int x = 1; int y = 2; printf("x is %i, y is %i\n", x, y); // x = 1, y = 2 swap(&x, &y); printf("x is %i, y is %i\n", x, y); // x = 2, y = 1 해결 } void swap(int *a, int *b) { int tmp = *a; *a = *b; *b = tmp; }포인터와 배열
- 기존의 썼던 배열들은 반드시 선언과 함께 크기를 지정해 주어야 했다. 하지만 포인터와 함께 배열에 접근한다면 배열의 크기를 조금 더 유동적으로 다룰 수 있게 된다. 단 주의할 점은 반드시 임시변수로 메모리를 할당하고 사용해야한다는 점이다. 처음 선언된 배열의 크기를 넘는 메모리에 접근한다면 심각한 버그를 일으킬 수 있다.
-
앞서 문자열을 다룰때처럼 배열의 첫 원소부터 자료형의 사이즈만큼 메모리의 주소를 옮겨서 접근하면 포인터를 배열처럼 다룰 수 있다. 다시 말해 문자열과 마찬가지로 배열로 선언된 변수는 배열이 사작되는 주소를 포인터로 가르키고 있는것과 동일하다.
// 배열과 포인터는 대체가 가능하다. #include<stdio.h> int main(void) { int arr[3] = {10, 20, 30}; printf("베열 인덱스: %d %d %d\n", arr[0], arr[1], arr[2]); // 10 20 30 printf("포인터 : %d %d %d\n", *(arr+0), *(arr+1), *(arr+2)); // 10 20 30 }// 또한 포인터를 통한 접근으로 배열의 크기를 좀 더 유동적으로 다룰 수 있다. #include <stdio.h> #include <stdlib.h> int main(void) { //int 자료형 3개로 이루어진 list 라는 포인터를 선언하고 메모리 할당 int *list = malloc(3 * sizeof(int)); // 포인터가 잘 선언되었는지 확인 if (list == NULL) { return 1; } // list 배열의 각 인덱스에 값 저장 list[0] = 1; list[1] = 2; list[2] = 3; //int 자료형 4개 크기의 tmp 라는 포인터를 선언하고 메모리 할당 int *tmp = malloc(4 * sizeof(int)); if (tmp == NULL) { return 1; } // list의 값을 tmp로 복사 for (int i = 0; i < 3; i++) { tmp[i] = list[i]; } // tmp배열의 네 번째 값도 저장 tmp[3] = 4; // list의 메모리를 초기화 free(list); // list가 tmp와 같은 곳을 가리키도록 지정 list = tmp; // 새로운 배열 list의 값 확인 for (int i = 0; i < 4; i++) { printf("%i\n", list[i]); // 1 2 3 4 } // list의 메모리 초기화 free(list);
realloc
- 위의 유동적으로 배열 크기를 바꾸는 과정의 malloc, for문, free를
realloc(TARGET, N * sizeof(int));(N = 4)로 단축해 표현할 수 있다.#include <stdio.h> #include <stdlib.h> int main(void) { int *list = malloc(3 * sizeof(int)); if (list == NULL) { return 1; } list[0] = 1; list[1] = 2; list[2] = 3; // tmp 포인터에 메모리를 할당하고 list의 값 복사 int *tmp = realloc(list, 4 * sizeof(int)); if (tmp == NULL) { return 1; } // list가 tmp와 같은 곳을 가리키도록 지정 list = tmp; // 새로운 list의 네 번째 값 저장 list[3] = 4; // list의 값 확인 for (int i = 0; i < 4; i++) { printf("%i\n", list[i]); } //list 의 메모리 초기화 free(list); }
자료구조와 알고리즘 주요내용 정리
선형검색
- 배열을 처음부터 끝까지 하나씩 살펴보며 그 값이 속하는지를 검색하는 방법이다.
이진검색
- 배열이 정렬되었다는 가정하에 중간 인덱스부터 시작하여 값음 검색합니다. 중간 인덱스 값이 찾으려는 값보다 크다면 더 작은 수들이 있는 쪽으로 더 작다면 더 큰 수들이 있는 쪽으로 중간지점을 쪼개 가며 검색하는 방법이다.
버블정렬
- 오름차순으로 정렬을 한다고 할때 1번째와 2번째 원소를 비교하여 큰값을 오른쪽으로 정렬하고, 2번째와 3번째, 3번째와 4번째, …, n-1번째와 n번째를 비교한뒤 정렬을 한다면 거품이 표면 위로 떠오르는 것처럼 가장 큰값이 수열의 가장 큰 값이 오른쪽으로 떠 오르게 됩니다. 이 과정을 이미 위치가 정해진 n번째 원소를 제외하고 다시 1번째 원소부터 n-1 번째 원소까지 실행한다면 두번쨰로 큰 수가 n - 1번째에 위치하게 되고 더 이상 정렬할 원소가 없을때까지 반복하는 방법이다.
선택정렬
- 정렬이 필요한 부분만을 스캔해 가장 작은 값을 찾고, 찾은값을 가장 부분수열의 가장 앞에 있는 인덱스와 값을 바꿔주는 방법이다.
6 3 8 5 2 7 4 1을 선택정렬을 한다면 가장 작은값을 찾아 1번쨰 원소와 바꿔준다.1 3 8 5 2 7 4 6중 이미 자기 위치를 찾은 1을 제외한 부분수열3 8 5 2 7 4 6에 대해서 1번의 과정을 반복한다.1 2 8 5 3 7 4 6중 1과 2를 제외한 부분수열8 5 3 7 4 6에 대해서 1번의 과정을 반복한다.- 모든 원소가 정렬될때까지 반복한다.
병합정렬
- 병합 정렬은 원소가 한 개가 될 때까지 계속해서 반으로 나누다가 다시 합쳐나가며 정렬을 하는 방식이다.
- 원소가 한개인 배열끼리의 정렬은 단순비교로 가능하다.
주요 알고리즘 O(상한), Θ(평균), Ω(하한)
| 이름 | O(상한) | Θ(평균) | Ω(하한) |
|---|---|---|---|
| 선형검색 | n | n | 1 |
| 이진검색 | log n | log n | 1 |
| 버블정렬 | n2 | n2 | n |
| 선택정렬 | n2 | n2 | n2 |
| 병합정렬 | nlog n | nlog n | nlog n |
- 빅오(Big-O, O): 알고리즘의 최악의 상황에서 시간 복잡도를 나타낸다. 상한 또는 빅 오라고 한다.
- 빅오메가(Big-Omega,Ω): 알고리즘의 최선의 시간 복잡도를 나타낸다. 하한 또는 빅 오메가 라고 한다.
- 빅세타(Big-Theta, Θ): 알고리즘의 평균의 시간 복잡도를 나타낸다. 평균 또는 빅 쎄타 라고 한다.
연결리스트
- 배열과 같은 자료구조는 자료를 할당할 때 인접한 메모리끼리만 할당이 가능하다는 단점이 있다. 이 단점 떄문에 배열은 크기를 유동적으로 만들기가 번거롭습니다. 그래서 포인터와 구조체를 활용해 그 값을 저장할 변수 number와, 다음 값의 메모리 주소를 저장할 포인터 변수 next를 합쳐 새로운 자료구조인 node를 만들고 이 node를 포인터로 쭉 늘어뜨려 연결시켜 놓은 자료구조를 연결리스트(LinkesList) 라고 한다.
- 연결리스트를 탐색 중 next가 NULL인 노드를 만난다면 해당 노드가 연결리스트의 끝임을 알 수 있다.
- 연관글: Single Linkedlist with python
- C 언어로 node 구조체와 링크리스트 구현
- n->number”는 “(*n).numer”와 동일한 의미이다. (Syntactic sugar)
#include <stdio.h>
#include <stdlib.h>
//연결 리스트의 기본 단위가 되는 node 구조체를 정의합니다.
typedef struct node
{
//node 안에서 정수형 값이 저장되는 변수를 name으로 지정합니다.
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정합니다.
struct node *next;
}
node;
int main(void)
{
// list라는 이름의 node 포인터를 정의합니다. 연결 리스트의 가장 첫 번째 node를 가리킬 것입니다.
// 이 포인터는 현재 아무 것도 가리키고 있지 않기 때문에 NULL 로 초기화합니다.
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리킵니다.
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1의 값을 저장합니다. “n->number”는 “(*n).numer”와 동일한 의미입니다.
// 즉, n이 가리키는 node의 number 필드를 의미하는 것입니다.
// 간단하게 화살표 표시 ‘->’로 쓸 수 있습니다. n의 number의 값을 1로 저장합니다.
n->number = 1;
// n 다음에 정의된 node가 없으므로 NULL로 초기화합니다.
n->next = NULL;
// 이제 첫번째 node를 정의했기 떄문에 list 포인터를 n 포인터로 바꿔 줍니다.
list = n;
// 이제 list에 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number와 next의 값을 각각 저장합니다.
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node입니다.
//이 node의 다음 node를 n 포인터로 지정합니다.
list->next = n;
// 다시 한 번 n 포인터에 새로운 메모리를 할당하고 number과 next의 값을 저장합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
// 현재 list는 첫번째 node를 가리키고, 이는 두번째 node와 연결되어 있습니다.
// 따라서 세 번째 node를 더 연결하기 위해 첫 번째 node (list)의
// 다음 node(list->next)의 다음 node(list->next->next)를 n 포인터로 지정합니다.
list->next->next = n;
// 이제 list에 연결된 node를 처음부터 방문하면서 각 number 값을 출력합니다.
// 마지막 node의 next에는 NULL이 저장되어 있을 것이기 때문에 이 것이 for 루프의 종료 조건이 됩니다.
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// 메모리를 해제해주기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해줍니다.
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}
트리
- 각 노드들의 연결이 계층별로 나뉘어 2차원적으로 구성되어 있는 자료구조 이다.
이진검색트리
- 이진 트리의 일종으로, 노드의 왼쪽 가지에는 노드의 값보다 작은 값들만 있고, 오른쪽 가지에는 큰 값들만 있도록 구성되어있는 트리이다. 이진 검색을 수행하는데 유리합니다. 재귀적으로 구현하기 알맞다.
- 이진 검색 트리를 활용하였을 때 검색 실행 시간과 노드 삽입 시간은 모두 O(log n) 이다.
//이진 검색 트리의 노드 구조체
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 ‘true’ 반환
else {
return true;
}
}
해시테이블
- 해시 테이블은 ‘연결 리스트의 배열’이다.
- 연결리스트들을 특징마다 분류하고 특징에 알맞는 배열의 인덱스에 연결리스트들 저장한다. 이때 특징에 맞게 분류하는 함수를 해시 함수(Hahs function)이라하고, 분류하는 작업을 해시라고 한다.
- 만약 해시 함수가 이상적이라면, 각 바구니에는 단 하나의 값들만 담기게 된다. 검색 시간은 O(1)이 된다.
- 메모리의 공간을 많이써서 시간복잡도를 낮출 수 있는 트레이드 오프가 존재한다.
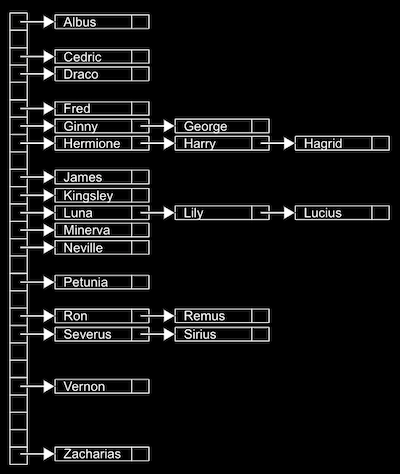
트라이
- 트리 형태의 자료 구조이다. 하지만 노드가 각각 배열로 이루어져 있다. Hermione, Harry, Hagrid 를 트라이로 저장한다고 가정하면 각 알파벳을 따라갈때마다 새로운 배열을 발견할 수 있다. 그리고 같은 알파벳 같은 순서를 공유하는 노드끼리는 같은 노드를 공유할 수도 있다.
- 값을 검색할때 걸리는 시간은 문자열의 길이와 동일하다. 그러므로 O(1)의 알고리즘이라고 할 수 있다.
- 단점으로는 메모리를 많이 차지할 수 있다는 점이 있다.
Leave a comment